stacking
Published 2025-05-15 • Updated 2025-05-16
Stacking trains several base models (level 0), then trains a level 1 meta-model that uses the predictions of the level 0 models as features.
Conceptual sketch based on the Predict Podcast Listening Time competition:
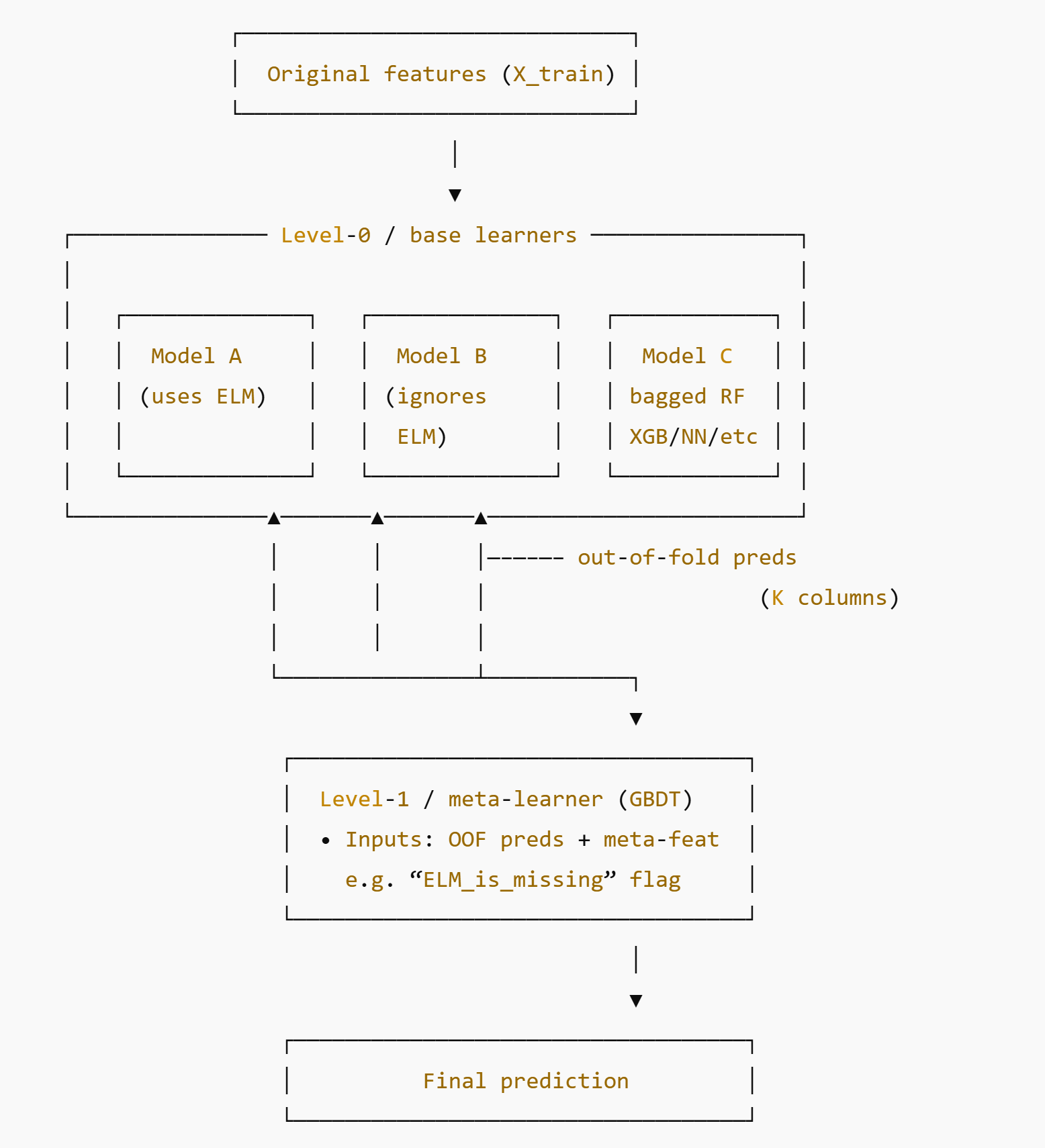
Each level 0 model outputs an OOF (out of fold) prediction for each row in the training data. Generally, more level 0 models are better, as long as they have sufficiently different approaches that capture different interactions. The level 1 model then trains on those OOF predictions, where each column in the meta-learner’s training set is the set of OOF predictions of one of the level 0 models. Meta-features can also be added at this point. The target feature remains the same as for the level 0s.
The benefit is that the predictions produced by the level 0s each capture their own set of interactions, and the level 1 can decide for each row which model weighting is best for the corresponding meta-features. Simplified example from the podcast predictor:
if ELM_is_missing == 1: # 11.6 % of rows y_hat = 0.15*ModelA + 0.75*ModelB + 0.10*ModelCelse: # 88.4 % of rows y_hat = 0.80*ModelA + 0.15*ModelB + 0.05*ModelCStacking a linear meta-learner without meta-features is equivalent to hill climbing.
Note that sometimes, the model levels are referred to as level 1, 2, 3, etc. rather than level 0, 1, 2, etc, such as here.
When stacking with a small number of models:
- pick genuinely different learners
- generate clean OOF predictions
- keep the meta-learner simple to prevent over-fitting